
And AI took that personally
My early (late?) thoughts on the enormous promise of AI, and whether some solutions are still in search of a problem.


Its development is “as fundamental as the creation of the microprocessor, the personal computer, the Internet, and the mobile phone. It will change the way people work, learn, travel, get health care, and communicate with each other. Entire industries will reorient around it. Businesses will distinguish themselves by how well they use it.”
The blockchain? Ha! Of course not. This is Bill Gates writing about artificial intelligence (AI).
AI hype has exploded over the past 6-12 months. But even within that context, the last few weeks have been extraordinary, with new releases from OpenAI (GPT-4), Google (Bard), Meta (LLaMA), Baidu (Ernie), Midjourney (V5), and Stanford (Alpaca), to name a few.1
For roughly the past month, I’ve been diving into AI and machine learning tutorials, YouTube videos, and code libraries (e.g. PyTorch, Fast.ai, etc.) to get a more hands-on feel for how neural networks work and how to fine-tune existing models for my own use cases. These experiences have left me with a few conclusions and predictions, and even more questions, about AI.
In no particular order:
AI is the revolutionary technology that crypto tried and failed to be
If you’ve had a couple glasses of wine and squint sort of hazily into the middle distance, the media hype cycle for artificial intelligence bears a vague resemblance to the cycle for cryptocurrencies and the blockchain. Because of this superficial similarity in the public reaction to these two technologies, I’ve already seen a number of people wondering aloud whether AI is just crypto’s successor as the next technology trend to burn brightly before withering away.
I’ll spare you the suspense: it’s not. I have no special insight into whether and when news organizations will tire of writing endless stories on AI2, but the underlying technology is here to stay.
The problem with cryptocurrencies, which are now nearly fifteen years old, has always been their glaring lack of real-world, legal use cases.3 AI, if anything, suffers from the converse scenario: artificial intelligence products have been proposed, prototyped, or even released in just about every fathomable domain and industry: detecting breast cancer, creating pharmaceutical candidates, chatting with humans, generating imagery, streamlining agricultural productivity, teaching languages, writing code, reviewing legal contracts, transcribing and translating audio, and tracking a Chinese spy balloon, to name just a few.
Akin to the birth of the Internet, the pace of AI innovation today is overwhelming: on a seemingly daily basis, new technologies and implementations are released that would have been incomprehensible mere months ago. For example, Stanford’s Alpaca large language model (LLM) can be run, albeit slowly, on a Pixel 6 smartphone and even a Raspberry Pi.
You’ll notice you don’t hear a lot of AI entrepreneurs tweeting “the technology’s still early!” all the time. It’s because they don’t have to.
Even so, many of today’s most popular AI products are effectively loss leaders

As much fun as it is to imagine French president Emmanuel Macron clashing with Parisian police over his own retirement age law (here’s another good one), this never happened: it was created using generative text-to-image AI tools like Stable Diffusion, DALL-E, or Midjourney.
Each of these products works relatively similarly: you type a prompt into a text box, e.g. “Emmanuel Macron pushing heavily armed riot police with smoke in the background.” And after thirty seconds or so of processing, the resulting image (or several of them) are displayed on your screen, as if by magic.
You can even make this:


This is all very cool. But it’s not clear how useful it will turn out to be.
There’s been much understandable handwringing about the effect that these (mostly) free services will have on the livelihood of genuine artists. (Don’t worry too much yet, though: just try reading the text on those cops’ hats.) And certainly on the margins, it’s easy to see how AI-generated images could damage the market for higher-brow artistic endeavors.
But a good chunk of today’s most popular AI products are more like sandboxes or (particularly impressive) demos than they are fully-fledged solutions to real-world problems. In fact, probably a better example of this than AI-created images is the product that kicked off all this craze in the first place: ChatGPT.
Microsoft, which has invested billions in ChatGPT’s creator, OpenAI, quickly incorporated the technology into its Bing search engine, where you can now chat with it, ask questions, and look up information. Incorporating an LLM-powered chatbot into search has ignited a ferocious race between Microsoft and Google, which just yesterday opened its counterpart to ChatGPT, called Bard, to the general public.
Again, very cool. But also, why?

No matter which way you look at it, Google’s top searches are overwhelmingly simple, usually two- to three-word terms, many of which signal a clear desire to find a very specific piece of information or web page:
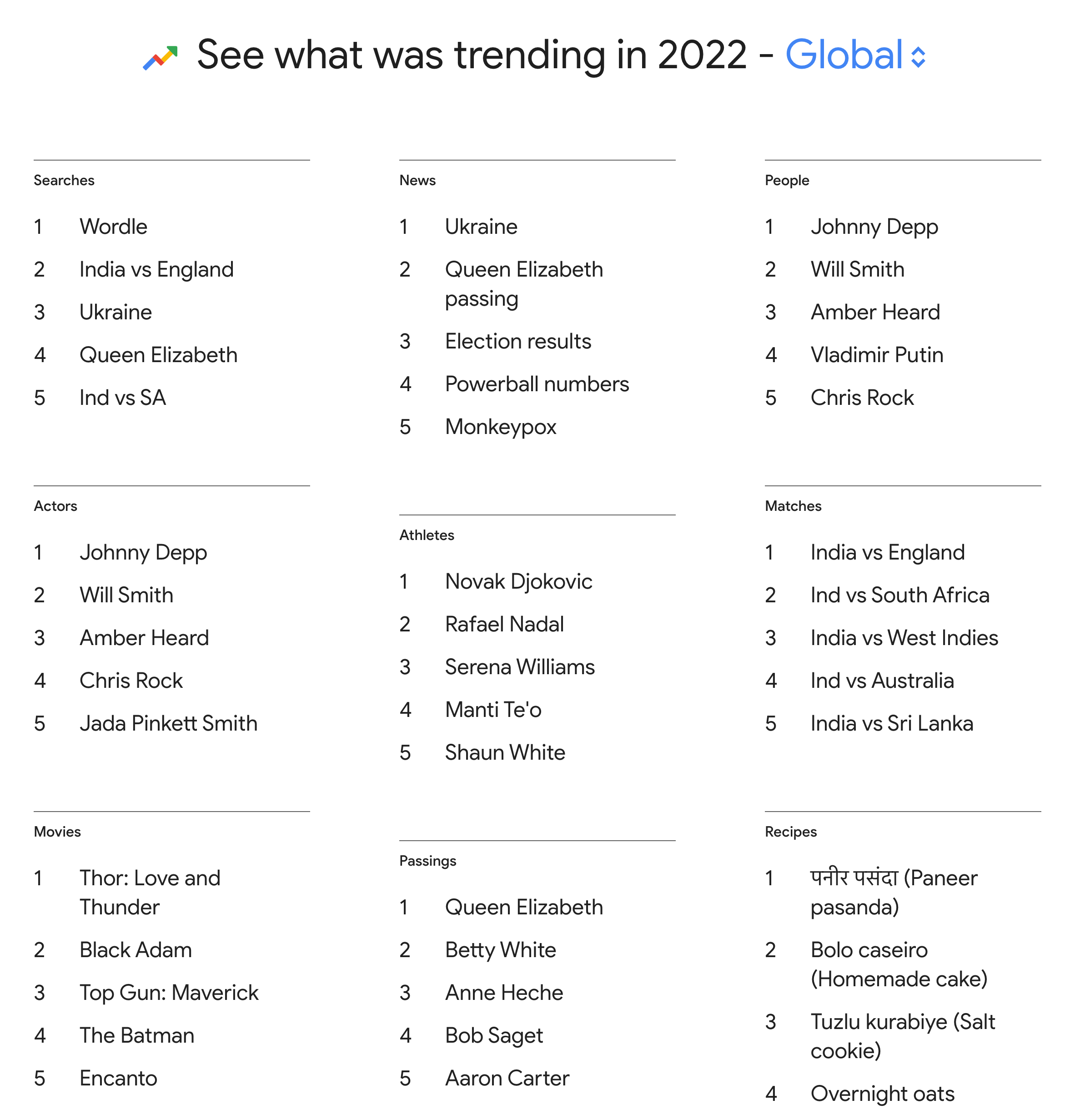
For most of these searches, using full-sentence chat to retrieve your answer would be significantly slower than just typing in a quick search term the old-fashioned way. And that’s to say nothing of the difference in cost, as OpenAI CEO Sam Altman acknowledged:

And this cost problem isn’t unique to OpenAI, but is actually common to virtually any large-scale application of GPU-intensive tasks. Alphabet chairman John Hennessy estimated that using chat would “likely cost 10 times more than a standard keyword search, though fine-tuning will help reduce the expense quickly.” (This last part is important, as costs on all facets of AI are likely to decline quickly as new efficiencies are found.)
It’s understandable why Microsoft might want to use its tiny search market share to force Google into ballooning its search costs in a bid to keep up with emerging technology. But it’s not as obvious (to me, anyway) how chat-enabled search will be superior to its legacy counterpart for the vast majority of user searches.
As with prior innovations, AI will often be mindlessly stapled onto legacy formats where it doesn’t make sense
If you watch shows on your computer — via Hulu or the ad-supported version of Netflix, for example — you may have noticed that the video ads are often exact duplicates of ones that appear on linear TV. Similarly, even today, decades after the birth of the Internet, most major newspapers’ web sites look and feel remarkably similar to their physical paper counterparts.4
This is because the easiest, lowest-effort way to implement new technology is usually to simply drag-and-drop it into a preexisting workflow or process. Frustratingly, this is often done with little to no thought expended on the applicability or usefulness of a new technology to a legacy format, which is why once-pioneering innovations — like Internet advertising — can very quickly feel stale and uninspired.
These failures of imagination happen in a variety of places, but perhaps nowhere is the stubborn refusal to learn from mistakes more endemic than in national news and journalism.
I already mentioned the static display of many of today’s digital newspapers. But this is hardly the only area where journalism leadership has stumbled into unforced errors centered on technology.5 I have previously covered the industry’s Charlie-Brown-and-the-football relationship with Facebook, in which news orgs fell for every conceivable pitch (most notably the “pivot to video”), no matter how foolhardy:

And they’re doing it again right now with AI. CNET was caught (very quietly) using artificial intelligence to help it write news stories, which resulted in 41 of the 77 involved articles requiring at least one correction. And last month, German publisher (and Politico owner) Axel Springer’s CEO Mathias Doepfner said that “artificial intelligence has the potential to make independent journalism better than it ever was – or simply replace it.”
Does it, though? I would posit that if your journalism can be replaced by a large language model, you were contributing negligible value in the first place.6 Doepfner's statement appears to be yet another case of confusing one of its news organization's revenue streams (an SEO-powered ad sales business) for its putative objective: educating readers.
This short-termism will happen over and over again in many industries, especially now that more companies with foundational AI models are creating API platforms that will enable other businesses to build on top of the same core technology. Christina Melas-Kyriazi of Bain Capital Ventures put it best: “If ChatGPT is the iPhone, we’re seeing a lot of calculator apps. We’re looking for Uber.”
Chaining LLMs together with other services and APIs seems like a high-potential area
One of the the things I’ve found ChatGPT most useful for — other than helping me write Python, which still feels as close to actual magic as anything I’ve ever experienced in technology — is in explaining things to me in a way I can understand, mainly because I can ask endless follow-up questions. For example, while taking tutorials on neural networks I often come across a technical concept I’m not sure I fully grasp, so I ask ChatGPT about it and keep querying for specific details until I feel I’ve more or less understood it.
The obvious problem here is that ChatGPT or Bard may be hallucinating an incorrect answer and has therefore misinformed me as well. Making matters worse, these hallucinations may be deliberately instigated by external actors:



One possible solution to this problem is to use LLMs as one piece of a more complex toolchain. Meta AI researchers submitted an academic paper last month titled “Toolformer: Language Models Can Teach Themselves to Use Tools,” which introduced…
…a model trained to decide which APIs to call, when to call them, what arguments to pass, and how to best incorporate the results into future token prediction. This is done in a self-supervised way, requiring nothing more than a handful of demonstrations for each API. We incorporate a range of tools, including a calculator, a Q&A system, a search engine, a translation system, and a calendar. Toolformer achieves substantially improved zero-shot performance across a variety of downstream tasks, often competitive with much larger models, without sacrificing its core language modeling abilities.
Similarly, LangChain uses a concept called “agents” to perform much the same type of functionality, joining the semantic power of an LLM with the specialized and/or up-to-date information available via external services. And a startup called Adept is building an “AI teammate” that can interpret your plain-English commands and turn them into actions in your browser tabs, like creating P&L columns in Google Sheets or adding a new contact in Salesforce.
This is speculative on my part, but combinatory tools such as these seem likely to have the highest real-world impact. Large language models are almost definitionally out of date the moment they’ve completed training. And yet it’s prohibitively expensive and time-consuming — or perhaps not even technically possible on today’s hardware — to keep training new iterations of the same model on a daily or hourly basis to keep up with everything new that’s transpired since. So the combined power of semantic understanding and specialized, updated data will enable AI to look and feel like a very smart human colleague, rather than a quirky chatbot awaking from a two-year coma.
The open vs. closed ecosystems debate is relevant yet again, with high stakes
OpenAI started out in 2015 as a nonprofit research organization, whose mission statement explicitly declared it “unconstrained by a need to generate financial return” and whose introduction blog post promised that “researchers will be strongly encouraged to publish their work, whether as papers, blog posts, or code, and our patents (if any) will be shared with the world.”
Over time, however, it shifted focus, swapping its non-profit classification in 2019 for a “capped-profit” one. It’s also accepted billions of dollars of external investment funds from Microsoft. Meanwhile, GPT-3 source code has not been publicly released, and, per The Verge, information surrounding the brand-new GPT-4 model is, if anything, even murkier:
OpenAI has shared plenty of benchmark and test results for GPT-4, as well as some intriguing demos, but has offered essentially no information on the data used to train the system, its energy costs, or the specific hardware or methods used to create it…
…Speaking to The Verge in an interview, Ilya Sutskever, OpenAI’s chief scientist and co-founder, expanded on this point. Sutskever said OpenAI’s reasons for not sharing more information about GPT-4 — fear of competition and fears over safety — were “self evident”:
“On the competitive landscape front — it’s competitive out there,” said Sutskever. “GPT-4 is not easy to develop. It took pretty much all of OpenAI working together for a very long time to produce this thing. And there are many many companies who want to do the same thing, so from a competitive side, you can see this as a maturation of the field.”
“On the safety side, I would say that the safety side is not yet as salient a reason as the competitive side. But it’s going to change, and it’s basically as follows. These models are very potent and they’re becoming more and more potent. At some point it will be quite easy, if one wanted, to cause a great deal of harm with those models. And as the capabilities get higher it makes sense that you don’t want want to disclose them.”…
…When asked why OpenAI changed its approach to sharing its research, Sutskever replied simply, “We were wrong. Flat out, we were wrong. If you believe, as we do, that at some point, AI — AGI — is going to be extremely, unbelievably potent, then it just does not make sense to open-source. It is a bad idea... I fully expect that in a few years it’s going to be completely obvious to everyone that open-sourcing AI is just not wise.”
Google’s Bard follows much the same pattern. Meanwhile, Meta AI initially granted access to its LLaMA models on a case-by-case basis to practitioners in specific fields such as academia and civil society, but the models quickly leaked online anyway. Stanford’s Alpaca models (which were themselves fine-tuned on LLaMA) are fully available.
What does all of this mean for the future of products built atop large language models? And does the mere presence of open-source, freely available LLMs make large-scale digital disinformation and data pollution inevitable?
Instinctually, I’m relieved that the tech giants with the deepest pockets and the most access to state-of-the-art GPUs don’t yet have a monopoly on generative AI technology. But the potential negative implications of freely available, low-cost, endlessly customizable content at scale — in text, image, and even video form — are enormous. For example, it doesn’t particularly strain the imagination to picture a 2024 American election season rife with made-up video footage, astroturfed social media campaigns, and artificially generated photos of politicians in compromising situations. Nightmare scenarios like these are almost enough to make you long for the impotence of crypto.
And that doesn’t even touch on the geyser of venture funding pouring into the industry.
Although Donald Trump’s (apparently imminent) indictment is a particularly likely candidate.
It’s always important to specify “legal,” as advocates frequently point to cryptocurrencies’ use as stores of value in countries with hyperinflation and capital controls. This may be true, but black markets in currency are not legal. On the other hand, the illegality of pumping-and-dumping unregistered crypto securities on retail traders has never stopped certain venture capitalists before, so perhaps this isn’t an issue.
There are, of course, exceptions. Back in the day, for example, Circa attempted to “atomize” the news by breaking it into bite-sized chunks of information that could be updated as a story developed, catering to an individual’s unique reading history and interests. But experiments such as these (as well as other attempts to branch out into newsletters, SMS interactions, etc.) have typically been more creative at the local or regional level rather than at the big national news brands.
Or, for that matter, on the content of their actual reporting.
Note that I am referring to replacing journalists with AI, rather than the more limited objective of incorporating AI into the journalism process to enable journalists to be more productive.
Uber's key innovation was skirting labor laws. So when VCs say things like "Were looking for the Uber of AI", what they really mean is "where looking for ways a company can use AI to mistreat it's workers without being fined for it".