
On Odd Lots, some guests are more perfect than others
Vibe-coding my way to public accountability.

The other day I was listening to one of my favorite podcasts, Bloomberg’s Odd Lots. The hosts, Joe Weisenthal and Tracy Alloway, had invited on economist Adam Posen to discuss his recent paper predicting 4% inflation by the end of 2026.
Listening to Posen enumerate the reasons for his heterodox position, I had a thought that has occurred to me many times over the years, whenever hearing or reading a bold call: I wish I had a way of remembering this later on to see if it comes true.
Well, now I do, and you do too. It’s called Odd Lots Oracle, and it’s publicly available to use as a web app.
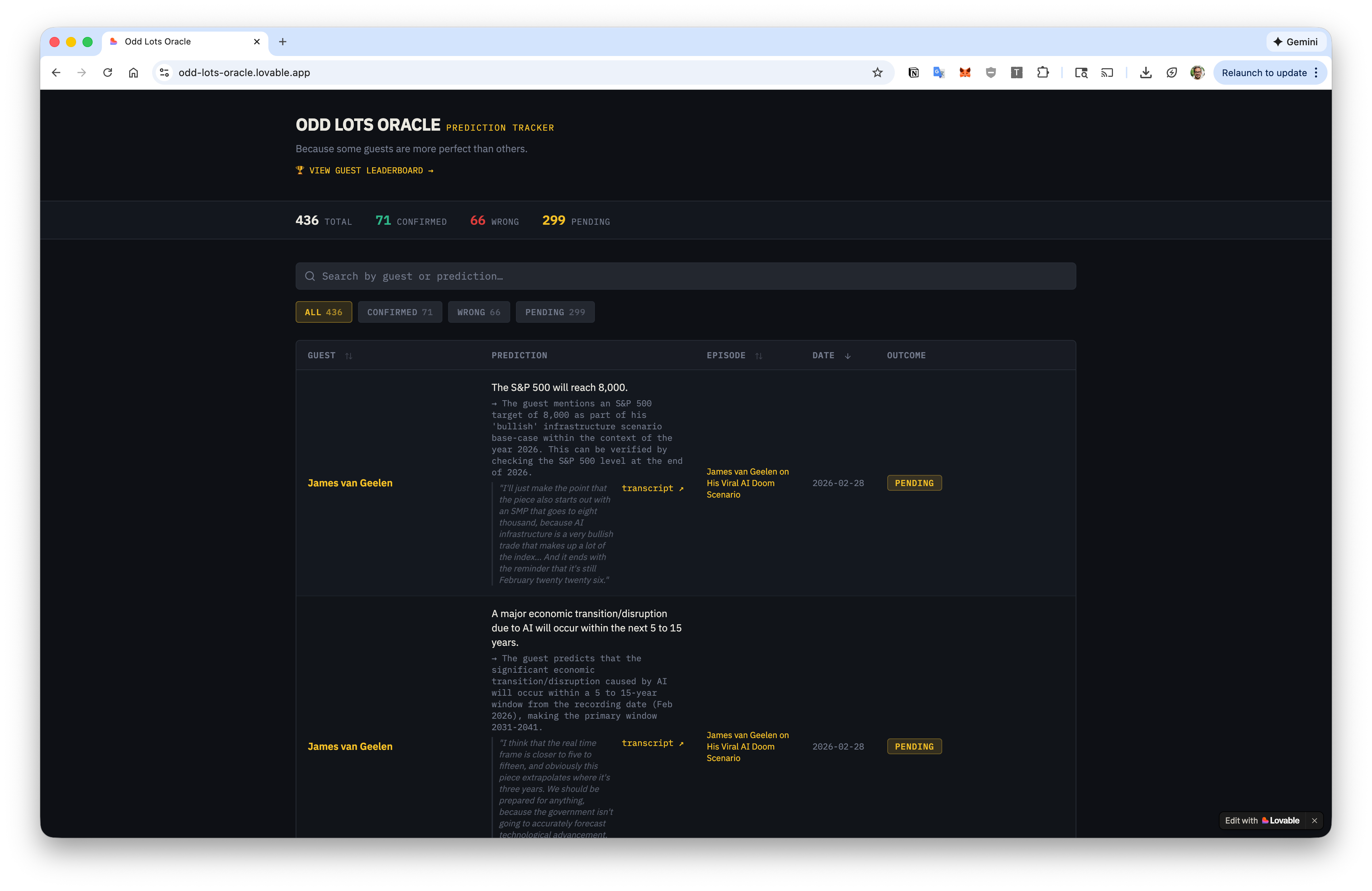
Odd Lots Oracle includes all Odd Lots episodes from the start of 2025 onward and allows you to search for guests, episode titles, and predictions made on the podcast. There’s even a guest leaderboard showcasing who’s been the most accurate predictor.
This post isn’t actually about Odd Lots
I mean, it sort of is. But it’s also about how AI is transforming what would be weeks- or months-long projects into workable prototypes within hours.
Maybe it’s the elderly millennial in me1, but I’ve had a long and fairly oddball obsession with quantifying accuracy of various kinds. Previous hobby horses of mine have included building apps to plot the Federal Reserve’s future-facing interest rate projections against what actually occurred, evaluate automated speech recognition accuracy, back-test tens of thousands of soccer bets to find the most precise sports bookie, and track the plausibility of a criminal cartel’s Tether’s stated financial assets being real, among others.
A common thread through all of those projects was lots of manual work to code the apps themselves, and then even more manual work to painstakingly build the datasets the apps analyze.2
Odd Lots Oracle was different. I started with a blank canvas in Lovable, the AI-powered vibe-coding tool. I then began giving it instructions. Grab the list of all Odd Lots episodes. Find the transcripts wherever available. If not available, transcribe them. Now search the transcripts for predictions made by someone on the episode. Finally, check whether those predictions came true or not.
There were wrong turns and misunderstandings and confusion, sure. But ultimately, there’s also now a product — and that happened orders of magnitude faster than it would have without AI.
PanAIcea? No. Tireless AIntern? Yes.
As a Claude Code / Codex / Gemini CLI user, I came in pretty skeptical: was Lovable just another thin API wrapper on top of an LLM?
In one sense, yes. Lovable sits on top of Gemini 3 Flash. So if the question is “couldn’t you build the same thing using Gemini CLI” (or Claude Code, or Codex), the answer is almost certainly yes. But Lovable has clearly spent time on polishing its very smooth UX, its built-in integrations are dead simple to use, and (perhaps most importantly for me) cloud hosting is baked in — all of which solved pain points that have previously stopped me in my vibe-coding tracks.
I’m a product manager, not a developer, but I’ve been writing code regularly since at least 2014. And yet my personal laptop is littered with the detritus of mostly functional web apps. The reason most of them stayed on my laptop, rather than being publicly released, is largely because even with all the cloud services that exist today, it’s still such a pain to deploy: even for a relatively simple app, you’ll need a web server, and probably a database server (e.g. Postgres), and potentially a storage service (e.g. S3, GCP, Azure, etc.) as well. Doing all of this takes time, and expertise I’m not even that interested in obtaining.
Instead, Lovable automatically suggested its ElevenLabs integration when I told its chatbot I needed automatic transcription, and it suggested Perplexity when I said I needed a way to verify whether the predictions came true. All I needed were API keys for each one, and it handled the rest. So far, this next-level handholding is a tier of no-code that even Claude Code and Codex don’t reach, and it’ll be interesting to see if they change course at some point to attract more non-technical users.3
That said, I’ll caveat this in bold: I have not personally validated most of the prediction outcomes. Of the ones I’ve spot-checked, the accuracy is decent but…spotty. (On the main screen, click the small flag icon next to any prediction to report an error! I’ll do my best to quickly correct it.) One of the most recent predictions it lists, for example, is James van Geelen calling for the S&P 500 to hit 8,000, which…is not really what he did at all.4 Elsewhere, it seems to have incorrectly marked Lev Menand’s prediction about Michael Barr as wrong. And those are just ones I noticed in a few minutes of scrolling.
So my point is: don’t take this as gospel. It doesn’t have my unreserved imprimatur: AI created it, after all.
Epilogue
Thirteen years ago, I published an essay titled “When Public Data Is Too Public,” where I noted the intense privacy uproar following “the recent decision by the Journal News, in the wake of the Newtown school massacre, to publish an interactive map displaying the names and addresses of gun permit applicants throughout two New York counties.”
Back then, in those halcyon days of emergent data journalism, the definition of ‘public’ appeared to be evolving very quickly:
But what is often forgotten in the rush to comprehend this new data landscape is that much of what is considered newly public has actually long been so, often for years or decades. The debate has thus shifted to unfamiliar ground, and the consequence is a panoply of mostly unsatisfying solutions.
Gun permit applications are a prime example of this newfound conception of public data. As Jack Shafer noted, “By its very definition, the public record is not private. Under New York state law, the information the Journal News obtained from Westchester and Rockland county authorities can be obtained by anybody who asks for it.” The only remarkable aspect of the map was that the newspaper organized the available gun permit applications database into an easily navigable online feature. The Journal News thereby bridged the gap between the public data and the public…
A prohibition on organizing public data into handy features fails to pass the laugh test, but simply ignoring the dangers altogether is just as naïve. (Indeed, in very short order, Journal News reporters soon found their own home addresses exposed online as retaliation for their efforts.)
The disappearance of obscurity that we are experiencing today with the AI revolution is perhaps even more monumental than what transpired just over a decade ago with the explosion of data journalism. Gun permit applications within a given jurisdiction are all conveniently filed in the same place — for example, the county courthouse. An enterprising reporter could simply give the clerk there a call, or drop in in person, and walk out minutes later with years of gun permit applications. Moreover, in technical terms, these applications are relatively structured data: everyone fills out the same form with the same fields, making the job of parsing them and turning them into a searchable database pretty straightforward.
But the idea that any throwaway comment you’ve ever made as a guest on any podcast (or written on a blog post, or said on a YouTube video) can be trivially and automatically resurfaced and fact-checked, even if you appeared on the podcast years ago, the episode had never been previously transcribed, the show has long since stopped running, and the predictions you espoused wouldn’t even be falsifiable until years into the future?
Well, that’s slightly terrifying. But it’s the world we already inhabit today. It’s the equivalent of committing a crime back in the 1960s and only being caught in 2026 when a distant relative submits their DNA to a commercial ancestry site. We are all now confronted with the prospect of opposition research, the likes of which used to require a fully staffed team on a well-funded political campaign. But the victim isn’t an elected official anymore: it’s you. It’s all of us.
Last summer I asked ChatGPT’s Deep Research tool to figure out where I’d lived over the course of my life. Depending on how you count, I’m currently in my eighth or so metropolitan area, and ChatGPT was able to scour the Internet and find enough fleeting references on truly random web sites5 to mostly accurately reconstruct my entire location timeline stretching back fifteen years. It’s enough to make you wonder about all the unstructured secrets hiding in plain sight.
Hiding for now.
Pretty hard to beat the Iraq war as a personal inspiration for trying to hold people accountable for public claims, but our current president is certainly giving us all a run for our money.
How annoying is it to manually add Fed dot plot data to a Postgres table, you ask? Really annoying! Those dots are ridiculously small and I was always worried I’d accidentally saved the wrong interest rate projection.
This is likelier to happen at OpenAI and Google than it is at Anthropic, whose Claude Code seems to over-index on enterprise customers.
The piece literally begins with: “What follows is a scenario, not a prediction.”
Including aggregator web sites that I’d never even heard of, much less visited myself.